As more artists come forward to condemn YouTube’s business practices, the video giant has taken to defending its content ID system, although the accuracy and honesty of its defense is questionable says Chris Castle.
___________________________
Guest post by Chris Castle of Music Technology Policy
An increasing number of artists are stepping forward to condemn YouTube’s sleazy business practices ranging from YouTube’s improbable royalty payments to Google’s legacy DMCA notice and shakedown business practices. YouTube has struck back with the usual squid ink trying to obfuscate Google’s absurdly ineffective Content ID and Content Management System (“CMS”), most recently to the New York Times.
YouTube’s theory according to the NYT is that independent artists (such as five time Grammy-winner Maria Schneider who graced our pages with her groundbreaking essay on YouTube’s sleaze) are not harmed by YouTube’s “catch me if you can” DMCA shakedown because Content ID–the principal tool that some artists and copyright owners use to block or monetize both UGC and official video assets on YouTube–is widely available. The implication being if those pesky artists would just use the tools YouTube provides, there would be peace in the valley with sunshine and puppy dog tails for everyone with happiness among the subjects of the Unicorn Kings.
YouTube says that about 8,000 companies and organizations have access to Content IDand that independents may get access through affiliated companies and industry groups.
See? The clear implication is that “independents” have nothing to complain about because they can get “access” to ContentID through “affiliated companies and industry groups”. “Affiliated” in this case means affiliated with YouTube (laughably called “partners”), and that means that the “companies and industry groups” have signed a ContentID license agreement which is essentially a nonnegotiable form contract imposed by Google.
Because Google wants to have the rights to use their IP all tied down.
Ahem.
So let’s start with what YouTube actually says about who gets ContentID:
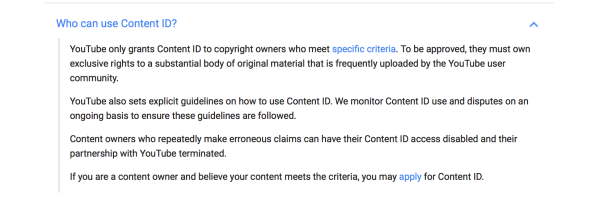
And what are the “specific criteria” that copyright owners have to meet for their “substantial body of original material”?

Here’s where that 8,000 number comes from:
As of July 2015, there are 8,000+ partners using Content ID — including many major network broadcasters, movie studios and record labels — who have claimed over 400 million videos, helping them control their content on YouTube and make money on videos containing copyrighted material.
Now quick–when you read that quote from the Times, did you think that YouTube meant 8,000 entities in the music business? In the US? Or did you not really focus on those nuances?
Right. I thought so.
So that quote from YouTube’s website arguably explains why there’s only 8,000 entities that have access to Content ID on a worldwide basis across all copyright categories (assuming that’s even true).
There’s at least five lies underlying that statement to the Times, all of which you’d miss if you didn’t have the inside baseball insight into the unnecessarily complex Content ID system–and as we know, complexity almost always hides fraud.
Lie #1: Show Me Where I Signed Your Social Contract
The first point is why should artists be required to even deal with Content ID or YouTube at all? If an artist never consented to being on the site in the first place, why should Google be able to just exploit their work without consent? Why shouldn’t Google have to have a contract with the artists to exploit their IP? You know, the way you have to be approved and have a license to use Content ID.
There is tremendous cost associated with engaging with YouTube at all whether you qualify for Content ID or you don’t. In fact, YouTube’s royalties are so crappy that it’s entirely possible that the total cost of doing business with YouTube exceeds any royalties you could make–because the cost of dealing with YouTube varies directly with the size of your catalog.
So why shouldn’t artists be able to just say no and keep all of their music (or other work product) off of YouTube? Every penny spent trying to block unauthorized videos is a penny spent for YouTube’s benefit. And why is it we have to pay for this?
The truth is that it is not at all apparent that declining the opportunity to license YouTube wouldn’t actually be more profitable than dealing with the incredibly screwed up Content ID and CMS system.
So let’s not assume that Content ID and notice and shakedown are the only possible outcomes here.
Lie #2: Using Content ID Is Not Free
Even though Google doesn’t charge for Content ID, using the system is hardly free, especially for “independents”. In order to get “access” to Content ID, an independent artist needs to contract with a claiming company–and pay that company anywhere from 20% to 50% of their YouTube revenue.
And let’s be clear–claiming companies exist to fix YouTube’s mistakes imposed on the world due to YouTube’s legacy and highly inefficient DMCA notice and shakedown business. Every penny spent by an artist through giving a claiming company a revenue share is a penny spent for YouTube’s benefit by an artist capitulating to the notice and shakedown onslaught.
So saying that “independents” have “access” to Content ID through a claiming company “affiliated” with YouTube is a grotesque oversimplification. There are claiming companies that operate at the more lucrative end of the YouTube doing channel management and MCN or near-MCN business for which they may operate their own in-house advertising sales staff.
The claiming companies in reach of “independents” necessarily have to take a larger share of a smaller revenue stream in order to operate. And here’s what they don’t do:
Block.
Why do they only monetize? Because that’s what a revenue share means–revenue. Using Content ID to just block videos (especially UGC) would only be available for a fee (since there’s no revenue if you block everything). Independent artists can’t afford to pay a fee to block on YouTube so they typically will capitulate and monetize.
And who benefits from that? YouTube.
Why would blocking require a fee for service? If an artist just wants to bail out altogether, then that artist would set the automated controls of CMS to block worldwide. In order to make that blocking meaningful, there would need to be a lot of manual care and feeding to account for UGC leakage through the very porous Content ID.
That would include techniques like pitch bending to use the curious speed controls on the YouTube player which seem to have one purpose–defeating Content ID.
This is what’s called a royal pain in the trade, so anyone doing that work would have to be paid for the hours and hours and hours it would take to accomplish it. Since the artist can’t afford to pay someone else to do that work, the artist would need to do it in all their spare time. Which of course will not be very effective or may not happen at all.
We call this the ennui of learned helplessness.
Lie #3: Artists Cannot Access Content ID
By using the word “access” when it comes to Content ID, YouTube is equivocating yet again. If you are an independent artist and your distributor has a CMS account (and that’s a small group), do you have access to Content ID?
No. At best, you can tell your distributor what you do and do not want monetized. They will only devote so much time to you, however, and they won’t do the manual claiming on UGC, etc., at least not until you get some pretty significant traction on YouTube (meaning over 5,000 views or so on a particular video).
Your distributor will not allow you to get your hands on their CMS or Content ID dashboards. There’s a good reason for this, which is that the way Google licenses Content ID there’s a good chance that the distributor (such as Tunecore or CD Baby) could never get enough seats for its particular CMS license to allow all the distributed artists to have individual access, and there’s no view in Content ID that would show one artist’s tracks without showing that user all the other artist’s tracks handled by that distributor.
Why? Because YouTube doesn’t design the system for “independents”.
Lie #4: Independent Songwriters are SOL
Notice YouTube never talks about independent songwriters having “access” to Content ID. The closest that an independent songwriter comes to getting access to Content ID is if they opted into the HFA YouTube license connected to the out of court settlement of the class action against YouTube that was a companion case to Viacom v. YouTube (and which wasn’t certified as a class, but is often referred to as a class action by people wishing to avoid using the legal term “putative”).
So ask independent songwriter who opted in to the HFA license how that “access” is working out for them.
Lie #5: Content ID Is Another Nondisplay Use of Other People’s Stuff
Google has made a subspecialty of acquiring data for one use and actually using it for other purposes–undisclosed purposes.
Remember “GOOG-411”? This Google product was the “free” Google directory assistance (very similar to Google Voice). Former Googler (and perhaps soon to be former Yahoo!er) Marissa Meyer told Info World years ago that GOOG-411 was not intended to be what it appeared to be:
You may have heard about our [directory assistance] 1-800-GOOG-411 service. Whether or not free 411 is a profitable business unto itself is yet to be seen. I myself am somewhat skeptical. The reason we really did it is because we need to build a great speech-to-text model … that we can use for all kinds of different things, including video search.
The speech recognition experts that we have say: If you want us to build a really robust speech model, we need a lot of phonemes, which is a syllable as spoken by a particular voice with a particular intonation. So we need a lot of people talking, saying things so that we can ultimately train off of that. … So 1-800-GOOG-411 is about that: Getting a bunch of different speech samples so that when you call up or we’re trying to get the voice out of video [such as from YouTube], we can do it with high accuracy.
That’s right–Google told you the product was doing one thing, but in actual fact it was always intended to be something entirely different. The real action was in the background where users couldn’t see it. If Marissa Meyer hadn’t let it slip in an interview, you might never have known.
If you have a Content ID contract, check out this language in paragraph 2:
By providing Reference Files, you grant Google a non-exclusive, royalty-free, limited license to (a) store, copy (including the right to make temporary cache and storage copies), modify or reformat, excerpt, analyze, use to create algorithms and binary representations, create ID Files and otherwise use those Reference Files, the ID Files and the associated metadata in connection with the System…
And there it is: “otherwise use”. Pretty broad grant of rights, eh? You could say that “in connection with the System” is limiting, but how would you ever know what “in connection with” means?
Remember Google Books? Ever heard of “corpus machine translation“? Google uses the scans of the tens of millions of books it stole from authors in the background to improve its translation algorithms. If the authors had brought their case about that, do you think the court would have been so quick to find this obviously massively commercial application a fair use?
Bevo ≠ Unicorn King
Once again, YouTube has scammed their way past artist objections such as those in Maria Schneider’s post and Irving Azoff’s open letter. I think this is partly because the whole Content ID system is such inside baseball–once you accept the idea that requiring artists to use these legacy DMCA tools is even acceptable, which I don’t. Reporters just don’t know what questions to ask.
Now they do.
